幼兒自閉症行為數據挖掘之跨領域人類行為建模
自闭症在人类行为数据挖掘研究
簡述自閉症行為建模的可行性與價值,首先得提到人類行為數據挖掘(Behavioral signal processing) 是利用一些隨手可得的影音資料來對於人類行為進行分析,例如:電話客服可以從客服與客戶間對話的情況來知道客戶是否有得到完善的解答或是客戶能滿意;在醫療上也可以借由數據分析的方式大規模的了解醫病關系,最終達到智慧管理的目的。
人類行為建模
這邊所描述之人類行為建模完全是指錄像與錄音。比方說在家長與受試者的互動過程(比方說玩積木、教學語言)我們錄音且錄影,並完全根據這些多媒體檔案分析一些現象,既可以免於發問卷那種框架式的問答,又可以有利於往後自動化發展。
自閉症
自閉症是人類學習發展遲緩的癥狀之一,通常在小孩學習能力未能達到一般正常小孩的時候家長就會帶去兒童心智相關科去檢測。在數據處理方面我們會將自閉症的數據分為三種族群:
- M1 : 年齡通常最小(2~5歲)還不會說話,通常這類的孩童會有很明顯的反應異常(不看人臉、不回應),但是實用性很高,不正常行為可以借由觀察他的專註目標來判斷。資料處理方面通常可以用錄像資料(或是眼動儀),因為小孩還處於可控制階段。錄音資料方面就不太有幫助,因為錄音需要孩童稍微有說活互動(spoken interaction)才比較好。
- M2 :稍微大一點的孩童可以從事一些社交舉動。這類的受試者在資料采集方面很難,小孩一定會不配合錄像鏡頭和錄音,時常要哄小孩或是提防他跑來跑去,在這之間就會在影音資料中加入很多不相關的訊息在裏面。分析這類資料通常不好用錄像,因為小孩容易跑出鏡頭,但是可以用戴在手上的手環資料搜集到聲音資訊,在經過資料清洗後的乾淨資料就可以從中分析小孩語音上的不正常特征,
- M3: 在定義中是有口語能力的受試者,M3通常是受過矯正教育的人,乍看之下與一般人很難看出差異,但是在與他對談後通常能感受的出有點不一樣。而對於受訓後的精神醫療人員來說,可以在短時間的對談了解其狀況。分析他的說話通常需要從語意上來分析,這類自閉症患者不像M2可以明顯判斷他們語言學習程度。一個更高層次的社交行為建模(局限片語用字、社交關系總體程度)就必須被開發。
自閉症評測
前面說過我們的資料都是錄像和錄影,內容是自閉症受試者和受訓過的醫療人員經過自閉症評測的過程。自閉症評測是大約一個小時的評量,首在。醫療人員會進行一系列的社交活動,為受測者打分,自閉症觀察評測便成了一個平台,激發出受測者在各項社交事件的表現。
語音訊號挖掘
說話人日誌(speaker diarization)
當我們在拍攝錄像和錄影的時候通常稱之為原始資料,必須通過資料結構化的處理(同步影音資訊、抓取重要片段)。說話人日誌在此就能將受試者(在此簡稱小孩)的聲音與受訓過的醫療人員(在此簡稱醫生)提取出來。往後可以單純分析小孩的語音或小孩對於醫生說過話的反應。
說話人日誌目前已成熟的做法為:
a. 提取說話人ivector:
Ivector 本身能記錄人類的聲紋特征 :
$$s = m + T\omega$$
S是我們錄到的聲音,m是平均的語言聲音,T是每個人說話的變異性,最後ω就是每個人的聲紋特征
b. PLDA 打分:
前述的Ivector是代表一句話的特征,PLDA就是為兩句話的相似程度進行打分,當我們能衡量那些話相似的時候,就可以用聚類的方式歸納出哪些聲音片段是來自同一個人的PLDA model:
$$\omega = \mu + \phi p + \epsilon$$
ω是上面提到的Ivector,∅是學習到的說話人子集合, p是個高斯假設,PLDA model 衡量那些話相似的方式為:
$$R(\omega_{1},\omega_{2})=\frac{p(\omega_{1},\omega_{2}|\Theta_{same})}{p(\omega_{1},\omega_{2}|\Theta_{diff})}$$
\(R(\omega_{1},\omega_{2})\) 相似打分來自兩片段相同的幾率\(p(\omega_{1},\omega_{2}|\Theta_{same})\)除以兩片段不同的幾率\(p(\omega_{1},\omega_{2}|\Theta_{diff})\)。
語音模型訓練
說話人日誌模型之訓練肯定要有龐大的訓練數據,並且要經過遷移式學習(transfer learning)適應到我們所錄得數據上。 在此,我用了海瑞天聲的人類對話語音數據訓練了ivector提取器,以及PLDA模型,另外用了
遷移式學習適應到我們的錄音數據上,效果如下:
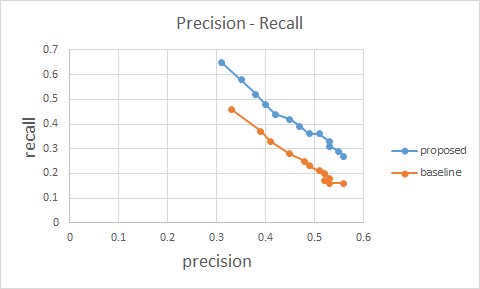
總結:
我做的自閉症科研是個跨領域研究,這類的研究非常重視結果的解釋性,否則很難給予醫療上建設性的建議。這個過程我認為從原始數據中先制造出二手數據(例如:說話人日誌),才能賦予我們之後的分析有根據的意義。